相关影像
型号

于2001年9月14日于日本,2001年11月18日于美国,2002年5月3日于欧洲发布。
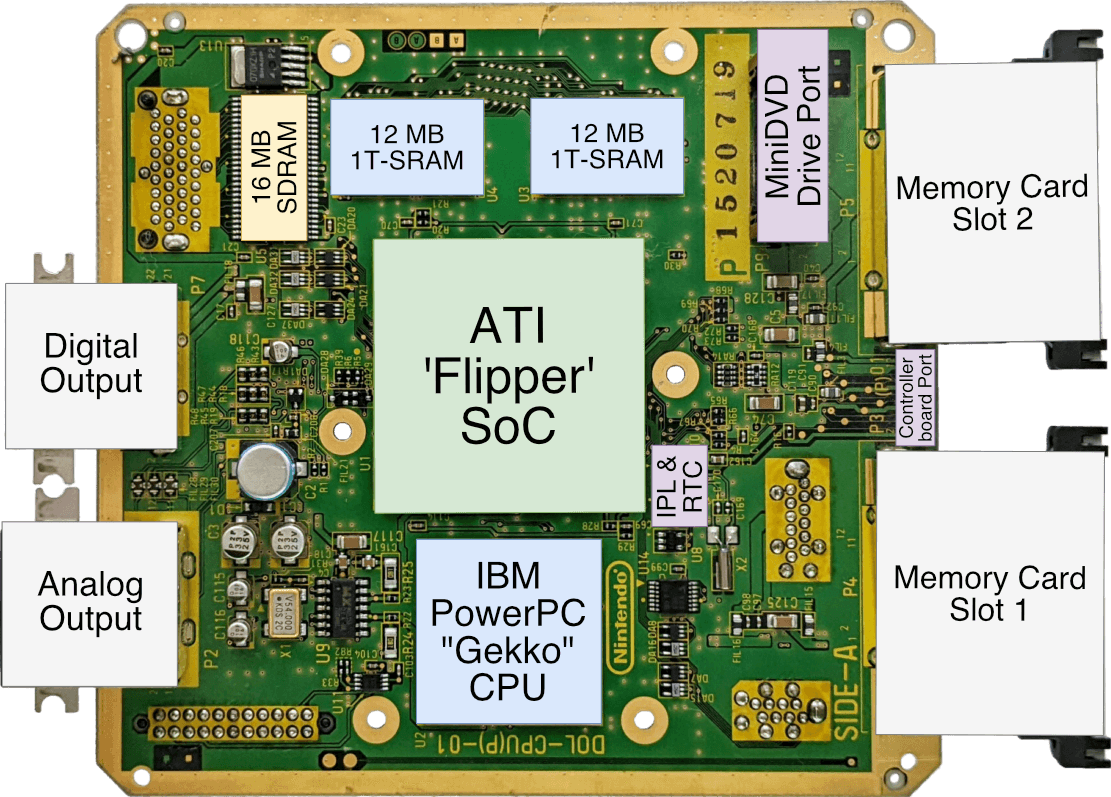
主板

取自已有的"DOL-CPU-10"型号,后来的型号去掉了串行端口2和数字输出接口。 编码器芯片、扩展、控制器和PSU槽位于另一侧。
图示
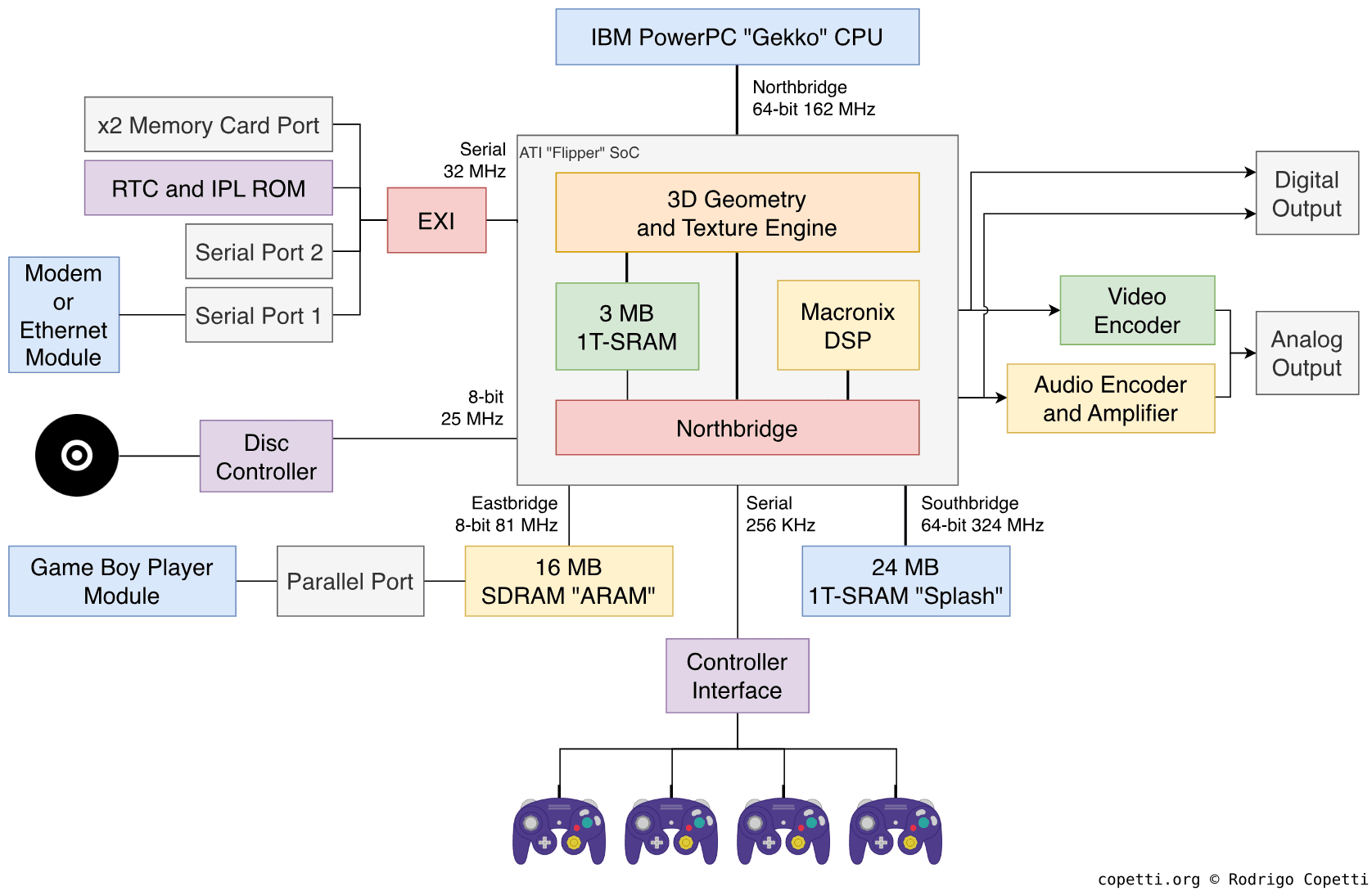
每一条数据总线都标注有带宽。
快速介绍
当“3D尝试”的日子已成为过去,任天堂的新产品与前代产品截然不同,它提供了一个干净而强大的突破,将为我们打开一扇通往全新、原创和前所未见内容的大门。
值得指出的是,这一架构的设计使其成为这一代最紧凑的硬件之一。 这一点在没有推出轻薄或者lite版本上得到了强调。
中央处理器 (CPU)
在SGI在图形市场失去主导地位之后,任天堂需要寻找新的合作伙伴。
一个很有希望的候选者是IBM:除了他们在大型机上的著名工作之外,他们最近还与摩托罗拉和苹果联手,创建了一个强大的CPU,足以与英特尔在PC市场的主导地位竞争。 这个合作的结果是一系列名为PowerPC的处理器,这些处理器被选中用于驱动99%的苹果Macintosh电脑、IBM的工作站和一些嵌入式系统。

为了理解这对GameCube意味着什么,我们首先来看看最终导致了PowerPC CPU的诞生的一系列创新。
PowerPC的起源
IBM是推动新兴RISC CPU设计进入主流市场的三大早期力量之一。 在80年代,当伯克利大学忙于开发“RISC CPU”,而斯坦福大学的学者们刚刚创立MIPS时,IBM已经生产了801和ROMP CPU。 这些是具有开创性但在商业上并不成功的芯片,它们实现了一系列后来被称为“RISC模型”的指导原则[1]。
商业里程碑
进入90年代,IBM再次尝试,推出了一系列新的UNIX工作站,名为“IBM RS/6000”,并在其中内置了一种新的内部RISC CPU:POWER1。 POWER1专注于指令级并行,具有吸引人的先进特性,如[2]:
- 一个完整的32位指令集,称为POWER指令集。
- 一个64位浮点单元。
- 哈佛缓存架构,这种架构将数据空间和指令空间分离,以增加带宽。
- 通过将其分布在三个独立单元(分支、定点和浮点)上,能够同时执行两个指令。 因此,POWER1被认为是一种双路超标量处理器。
- 静态分支预测,它将控制冒险转化为加速执行的机会。
- 通过寄存器重命名,实现浮点操作的乱序执行[3]。 总的来说,这大大增加了CPU每单位时间执行的指令数量(并处理了数据冒险)。
- 核心设计源自IBM的大型机时代,当时它以Tomasulo算法的形式发布,并随后在IBM System/360(1966年)上实现。 通过POWER1,IBM成功将其部分技术带到了工作站设备上。
然而,POWER1 CPU是一个由多个芯片组成的大而昂贵的包。 因此,在接下来的尝试中,IBM将其设计缩小,以适应单个芯片。 虽然仍然遵循POWER指令集,但代价是采用了32位浮点单元、冯·诺伊曼缓存架构,并恢复到顺序执行。 这个新的芯片被称为RISC单芯片(RISC Single Chip,“RSC”),并与他们的RS/6000工作站的低端系列一起出货。
面向普通用户

在IBM开发这些技术的过程中,他们还同意与苹果和摩托罗拉联手,共同对抗英特尔-微软在桌面市场的垄断,形成了AIM联盟。 因此,一个新的项目应运而生,旨在低端市场中打造一个具有竞争力的CPU。 这个项目将融合三家公司提供的知识产权,包括:
- IBM的RSC处理器设计。
- 摩托罗拉的总线架构(在他们的内部RISC处理器Motorola 88110中找到)。
- 苹果和摩托罗拉对终端用户需求的了解。
摩托罗拉88110团队的一员,Keith Diefendorff,被招募为首席架构师,并在1993年,产生了下列的项目最终成果:
- PowerPC指令集:POWER的一个子集,增加了乘法指令,支持对称多处理器设置和可选的64位模式。
- PowerPC CPU,一个新的桌面CPU系列,开始于PowerPC 601。 这是RSC微架构的成本效益版本。
- 摩托罗拉也完全放弃了88000 CPU的开发,转而专注于这个新系列。
PowerPC的流行
为了确保新系列既在技术上具有竞争力,又在商业上可行,PowerPC 601试图将某些指令级并行的先进技术带给大众,其中值得一提的包括[4]:
- 实现了POWER和PowerPC两种指令集,以帮助POWER开发者过渡到PowerPC。
- 采用三路超标量执行,使用三个独立的执行单元(FPU、分支和ALU)[5]。 这比以前的设计有所改进。
- 基于摩托罗拉的设计,一种新的总线设计被称为总线接口单元(Bus Interface Unit),提供:
- 一个64位数据总线和32位地址总线,前者对于利用超标量能力至关重要。
- 突发传输(Burst transactions),允许用单条指令传输32字节内存(L1缓存的大小)[6]。
- 内存管理单元(MMU),在同一封装中提供虚拟内存。
对于终端用户来说,这个新的CPU现在可以在IBM的低端RS/6000系列和苹果的新系列Macintosh电脑“Power Macintosh”中找到。
当代产品
PowerPC 601旨在为PowerPC系列积累势头,但在接下来的几年中,微架构经历了动荡的变化。
各自发展
601一上市,摩托罗拉和IBM就决定分别开发后续一代。 这意味着将是一个完全独立的PowerPC实现,不再包含任何POWER ISA的元素,并形成两个不同的产品系列[7]:
- 低端的PowerPC 603由摩托罗拉领导开发,面向便携式市场。 为此,它提供了一个较小的L1缓存(现在基于哈佛架构),两个额外的执行单元,并且不支持多处理器。 这些设计决策导致整体消耗率为1.8-2.0瓦[8]。
- 高端的PowerPC 604由IBM领导开发。 以高昂的价格和高功耗(14.5-18.5瓦)为代价,它提供了先进的并行能力(类似于MIPS),如4发射执行,恢复了乱序执行,动态分支预测和多处理器支持[9]。
尽管603应该因其电源效率而脱颖而出,但现有的商业应用程序最终掩盖了其能力。 例如,苹果的软件架构仍然依赖于模拟68000指令,这被603的小缓存大小限制住了。
顺便提一下,IBM开发的PowerPC 4xx系列原本是作为微控制器解决方案,而非桌面CPU[10]。 这些芯片配备了小型缓存,并且没有包括像MMU和FPU这样的复杂模块。 不过,这个系列提供了可定制封装,以便根据制造商的需求进行适配。 尽管如此,虽然4xx系列对本文主题而言并非重点,但值得注意的是,一个知名的竞争对手曾采用该系列来处理一些次要任务。
再次合作
然而,最终结果表明,第二代的桌面PowerPC芯片在成本上要么过高,要么在性能上无法与英特尔的处理器竞争。 因此,苹果让IBM和摩托罗拉再次合作,推出了一个新一代的统一设计,将两者的优点结合起来。 节能的603被选为新型设计的基础。 为了改进这个基础,采取了某些决策:
- 通过提供更大的缓存和高内存带宽来克服其局限性。
- 结合604的设计理念,如动态分支预测和乱序执行(目前仅限于内存操作)。
- 实现新的增强功能,如额外的ALU以实现更大的并行性。
这成为了750系列,被苹果作为PowerPC G3推广。 从那时起,IBM和摩托罗拉继续致力于750系列的变体和增强。 这些改进主要集中在更高的时钟速度、更大的缓存和更小的制造工艺。
有趣的是,总是最节能的CPU能够经受住开发动荡的考验,这一点后来也被其他公司(MIPS、英特尔和ARM)所证实。
乐队解散
随着时间的推移,这三家公司之间的距离越来越远。 在PowerPC G3发布两年后,摩托罗拉独自推出了一个名为7400的新系列(苹果将其命名为G4)。 这个系列的特点包括:一个64位浮点单元;一个更快的总线架构,称为“MPX”;一组称为“Altivec”的SIMD指令。 尽管它在桌面市场很受欢迎(这要归功于苹果),但IBM只专注于其专属的POWER CPU系列。
几年后的2003年,摩托罗拉最终放弃了CPU业务,并剥离了其半导体部门,导致飞思卡尔公司的成立。 后者对开发PowerPC芯片也不感兴趣,因此AIM联盟走到了尽头。 尽管如此,苹果仍然需要新的CPU,因此IBM通过缩小其POWER4设计,继续了继承线,推出了PowerPC 970 CPU(也称为“G5”)。
这就是历史部分的结束。 现在,是时候来看看GameCube的独特CPU了(它位于750/G3和7400/G4之间)。 从现在开始,我将专注于GameCube硬件,但如果你对这个插曲感兴趣,你可能会想接下来阅读PlayStation 3、Xbox 360和Wii U的研究。
PowerPC Gekko芯片
回到2001年,任天堂需要一款既强大又便宜的处理器。 为了满足这些要求,IBM采用了其过去的一款设计,一个增强版的G3,称为PowerPC 750CXe(可以在2001年初夏发布的晚期iMac G3中找到),并对其进行了加强,增加了游戏开发者会喜欢的能力。 结果就是PowerPC Gekko处理器,主频为486 MHz。

让我们来看看是什么让Gekko如此特别,为了做到这一点,我们首先需要了解750CXe的特点。 现在,回顾了PowerPC的历史,你可能会发现很多信息与之前的设计重叠(这就是这些研究的目的!)。 话虽如此,750CXe提供了[11]:
- PowerPC指令集架构:这一点不足为奇。 唯一额外的信息是750CXe实现了v1.10规范。
- 外部64位数据总线:正如你之前所看到的,虽然ISA可以适应32位总线,但我们仍然需要在不降低性能的情况下移动更宽的数据块。
- 三发射超标量:如果所需的单元可用,CPU可以在管道的同一阶段处理多达两个指令。 如果队列中包括分支指令,可能同时处理的指令数量增加到三个。
- 乱序执行:CPU可以重新排列指令的顺序,以使其所有单元都保持工作状态,从而提高效率和性能。
- 两个整数单元: 与超标量和失序模型相结合,可增加单位时间内完成的整数运算次数。
- 拥有32位和64位寄存器的集成浮点运算单元:加速浮点数和双精度浮点数操作。
- 四级流水线(带有额外的优点): 这里是先前有关指令流程的简介。 在750CXe中,浮点运算被分为三个更多的阶段(总共7个阶段),而装载存储操作被分为两个阶段(总共5个阶段)。
- 总的来说,这增加了指令吞吐量,而不会失控.
此外,该CPU还包括专用单元,可加快特定计算速度[12]:
- 分支预测单元: 每当需要评估一个条件(这个条件会决定CPU是否应该选择路径’A’或路径’B’) 时,CPU会根据先前的执行情况选择其中一条路径,然后再评估条件。 如果预测正确,CPU会节省一些时间;如果不正确,它将会回退并按照正确的路径执行。
- 专用存-取单元: 它将操作寄存器的单元与处理主存储器的单元分开。
- 集成内存管理单元(MMU): 将来自CPU的所有内存访问进行接口处理。
- 以前的游戏主机在制造上包括这个组件作为另一个协处理器,而现在MMU已经集成在同一芯片内,从而降低了制造成本。
当然,还包括了一些高速缓存以加速内存带宽:
- 64 KB一级高速缓存(L1 cache): 分为32 KB的指令缓存和32 KB的数据缓存。
- 256 KB二级高速缓存(L2 cache):它可以装载指令和数据,这大大提高了带宽。
IBM的改进
虽然之前列出的特性受到很高评价(与之前的一代相比),但这款CPU在游戏性能方面仍然落后于其他处理器(不要忘记这仍然是一款通用用途的CPU,在处理电子表格方面表现出色,但在物理运算方面一般)。 为了弥补这一点,IBM添加了以下的调整来构建Gekko处理器 [13]:
- 增强的指令集,包括50条新的SIMD指令:这些指令可以在一个周期内操作两个32位浮点数或一个64位浮点数。 因此,新的SIMD指令将加速向量计算,特别在几何变换过程中非常有用。
- 32位浮点寄存器:这些浮点寄存器与新的SIMD指令一同引入。
- 写入汇集管道: 可用的特殊内存写入机制。 如果启用,它不会执行单拍(single-beat)传输,而是将所有内存写入请求保存在 128 位字节的缓冲区中,直到缓冲区满25%,然后使用一种称为突发传输(burst transaction)的技术执行写入请求,这种技术可以一次性移动32字节的数据块。
- 正如您可以想象的那样,通过充分利用可用的总线,这可以节省大量的带宽。5
- 锁定的L1缓存: 程序可以占用16 KB的L1数据缓存用作“暂存区”(极快速的内存)。
除了处理游戏逻辑(物理、碰撞等)外,这些增强功能将使CPU能够以可接受的性能实现图形流水线的某些部分(几何变换、光照等)。 这非常重要,因为GPU只能加速有限的一组操作,因此最终的结果不受GPU的限制所制约。
是进步还是退步?
在您的N64的文章中,您提到该系统有一颗64位的CPU,但GameCube的CPU是32位的。 Nintendo是否降级了他们的游戏机呢?
事实上,Gekko实现的是32位PowerPC规范,而MIPS R4300i可以在32位和64位模式之间切换。 要回答这是否是一种改进,您需要问自己一个问题:为什么需要’64位’?
- 处理超过4 GB的内存→对于GameCube这种拥有有限内存位置的设备来说,并不是必要的。
- 操作更大的数据块并减少周期和带宽的使用→通过Gekko的新SIMD指令、64位FPU和数据总线以及写入汇集管道来实现的。
- 为了提出更多的宣传术语→是啊… 我觉得这已经不能说服人们了。
正如您所看到的,GameCube已经享受到了64位系统的优势,尽管它并没有被称为’64位游戏机’。 这正是为什么您和我不能仅通过’位数’来总结两台复杂的机器。
巧妙的内存系统
在设计下一代架构时,任天堂的架构师们对他们之前的设计进行了事后分析,并发现在使用统一内存架构以及一些高延迟组件(如RDRAM)时,导致了最大的瓶颈之一(几乎50%的CPU周期被浪费在空闲状态)[14]。 此外,多个独立单元的加入也导致了对内存总线的竞争。
因此,GameCube的设计者提出了一种新的内存系统,严格基于提供专用内存空间和使用低延迟芯片。 采用新设计后,GPU和CPU将不再争夺相同的内存(导致填充率问题),因为GPU现在拥有自己的内部内存,而且速度惊人。 另一方面,GPU仍将负责对I/O的访问进行仲裁。
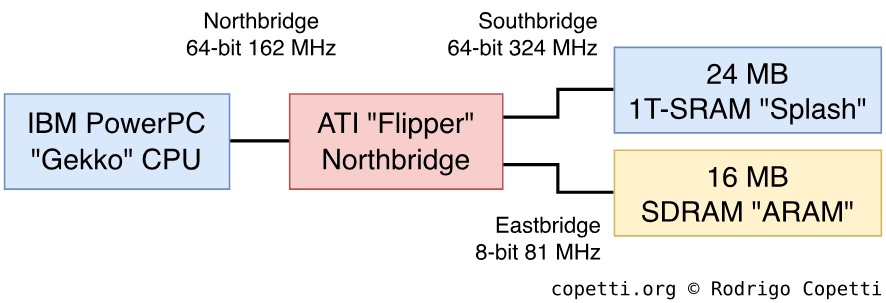
这样系统就有了两条主要总线:
- 北桥(Northbridge): 64位宽,连接CPU和GPU。 它的运行速度是CPU时钟的3倍,因此必须对任务进行优化,以减少对GPU的依赖。 DMA和高速缓存等其他组件可能会派上用场。
- 南桥(Southbridge): 它也是64位宽,将GPU与24 MB,称为“Splash”的1T-SRAM连接起来。 这种类型的RAM由DRAM(最常用的类型,但也更便宜、更慢)制成,但通过额外的电路进行了增强,使其表现得像SRAM(更快、更贵,主要用于高速缓存)。 总线速度是GPU的两倍,这可能是为了让GPU在CPU和主内存之间提供稳定的带宽。
此外,这种设计还包含一条额外的(但并不常见的)总线,可以在其中找到更多内存:
- 东桥(Eastbridge): 它将GPU与另一个名为音频RAM(Audio RAM,“ARAM”)的内存芯片连接起来[15]。 它提供16 MB的SRAM供一般用途使用,这对于备用内存来说是相当大的。 不过,总线不能通过正常方式(内存地址)访问。 相反,它连接到一个8位串行端点(时钟频率比GPU慢两倍,比CPU慢四倍),只能通过DMA访问。
总的来说,这意味着虽然ARAM提供了相当大的内存容量,但它将仅限于不那么关键的任务,如充当音频缓冲区或被某些配件使用(在I/O部分中解释)。
充分利用ARAM
到目前为止,我们已经看到,从纸面上看,该机的内存能力无疑优于前代产品,但仍有改进的余地。 例如,任天堂本可以安装更多硬件,将ARAM整合到 CPU 的内存映射中。
与此相关,我们再来看看Gekko中使用的MMU。 CPU采用32位地址总线,最多可访问4 GB内存,但系统中的内存却远远达不到这个数量。 因此,为了防止出现未填充(和不可预测)的内存地址,“虚拟内存”寻址被默认激活,用更安全、易缓存和连续的“虚拟”地址映射来掩盖物理地址[16]。
为了实现这一功能,Gekko(以及其他PowerPC架构)通过以下过程将虚拟地址转换为物理地址:
- 执行块地址转换(Block Address Translation,BAT):有8对可编程寄存器(4对用于数据,4对用于指令),每对寄存器将一个虚拟地址范围映射到一个连续的物理地址范围。 如果在这些范围内找到物理地址,MMU就会尝试查找。
- 如果BAT不起作用,则读取页表: MMU还存储了一个表,用于编目页面(虚拟地址块)的物理地址。
- MMU读取页表可能需要一些时间,因此需要一个转译后备缓冲区(TLB)来缓存最近的读取。
- x86或MIPS等其他架构也提供分页功能,但并非所有架构都提供TLB。
- 最后,如果请求的虚拟地址仍然无法转换,那么MMU就会在CPU中触发“分页错误”异常,并让操作系统决定下一步该怎么做。
那么,这对开发人员有什么用呢? 原来,任天堂发布了一些库,可以在分页的帮助下使用ARAM扩展主RAM。 简而言之,ARAM是不可寻址的,但CPU可以调用DMA从ARAM中获取和存储数据。 因此,CPU可以将页面从主RAM中移出,为其他资源腾出空间,并将其暂时存储在ARAM中。 之后,每当发生页面故障时,操作系统包含的一些例程就会用于查找ARAM中丢失的页面,并将其恢复到主RAM中的原始位置。
总之,通过一些巧妙的技巧,这些通用功能使GameCube游戏能够享受比技术允许值更多的内存,从而达到更高的质量水平。 不过,需要注意的是,这些技巧可能会带来一些性能损失(尤其是在想当然的情况下)。
图形
这是这款游戏机最关键的部分之一,它基本上让GameCube成为了GameCube。
这款游戏机GPU的历史有一些有趣的联系: N64的SoC(RCP)的开发主管Wei Yen后来成立了ArtX公司,并与任天堂签订了开发下一代芯片的合同:Flipper。

与上一代产品相比,ArtX 有了很多改进,例如,子系统被严格简化为单核(但功能强大)。
在开发过程中,ArtX被ATI收购,六年后ATI又被AMD收购。 因此,你会在游戏机壳子正面看到ATI的贴纸。
架构设计
Flipper是一个处理多种服务的复杂单元[17],所以现在让我们把重点放在图形组件上(因为它负责让我们的几何图形栩栩如生)。 我们将这一区域称为GPU或图形引擎,如果你一直在阅读N64的文章,我只是想告诉你,这个核心现在已经可以正常工作了,所以程序员无需担心要注入代码才能让它工作。 不过,还有一些有趣的部分可以定制。
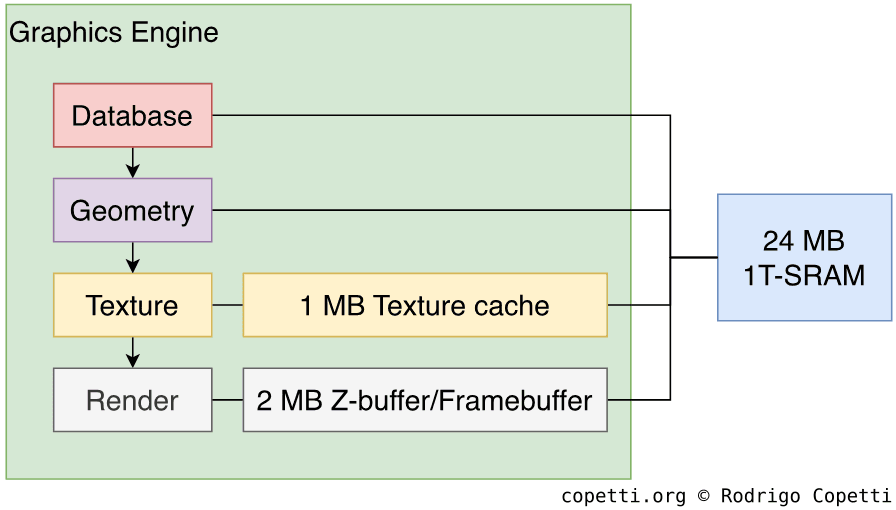
与往常一样,为了在屏幕上绘制一帧图像,我们的数据将通过GPU的流水线传输。 数据会经过许多不同的组件,我们可以将其分为四个阶段:
数据库
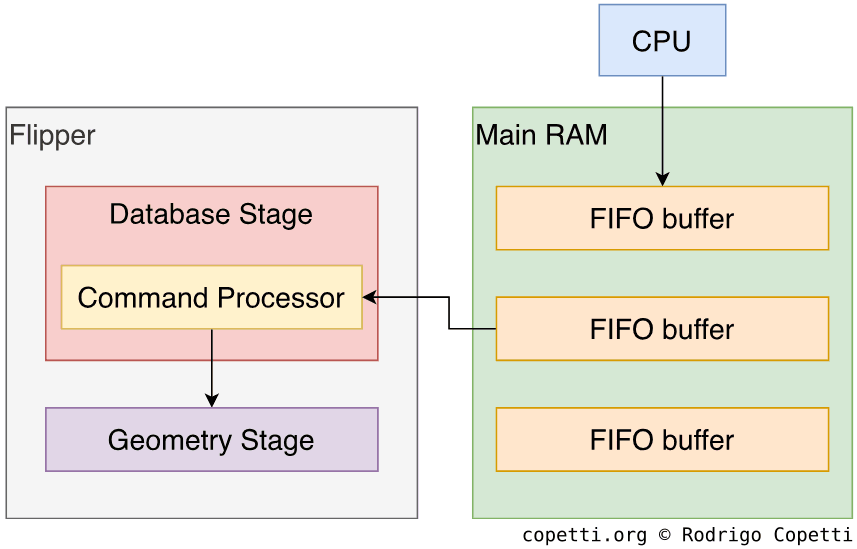
CPU和GPU通过主RAM中固定长度的FIFO缓冲区相互通信,这是CPU编写绘图命令的预留部分,GPU将读取(并最终显示)这些命令,CPU和GPU本身都支持这一功能。
此外,CPU和GPU不必同时指向同一个FIFO,因此CPU可以在GPU读取第一个FIFO的同时填充另一个 FIFO[18]。 这样可以避免空转。
在复杂的场景中,发出单个命令来构建我们的几何图形会变得非常繁琐,因此官方库中包含了一些工具,可以从游戏资产中生成所需的显示列表(预编译的FIFO命令集),只需将这部分复制到RAM中,GPU就能有效地显示它们。
GPU包含一个命令处理器,负责从FIFO中获取命令。
几何
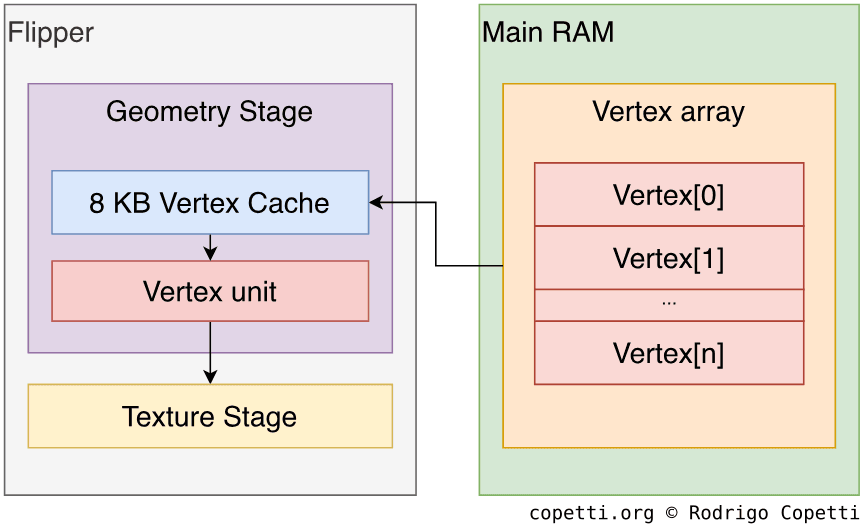
在这里,基元会根据所需的场景进行相应的形状转换,并为光栅化做好准备。 引擎使用专用的顶点单元(Vertex unit,“VU”)来完成这项工作。
有两种顶点模式可用于处理通过FIFO发送的基元:
- 直接模式:CPU 会向每个FIFO条目发送所有需要的属性(位置、法线、颜色、纹理坐标或矩阵索引)。 在数据已缓存的情况下非常有用。
- 间接模式:FIFO条目包含一个索引值,用于指定属性信息在RAM中的位置,因此顶点单元需要自行查找。。 这些数据的结构是一个数组,因此顶点单元要遍历这些数据,每个顶点条目都必须指定数组的起始位置(基指针)、每个条目的长度(步长)以及顶点所在的位置(索引)
加载完成后,可以对基元进行变换、剪切、光照(每个顶点都有一个RGB值,该值还可以进行内插,用于高洛德着色(Gouraud Shading)),最后进行投影。
纹理
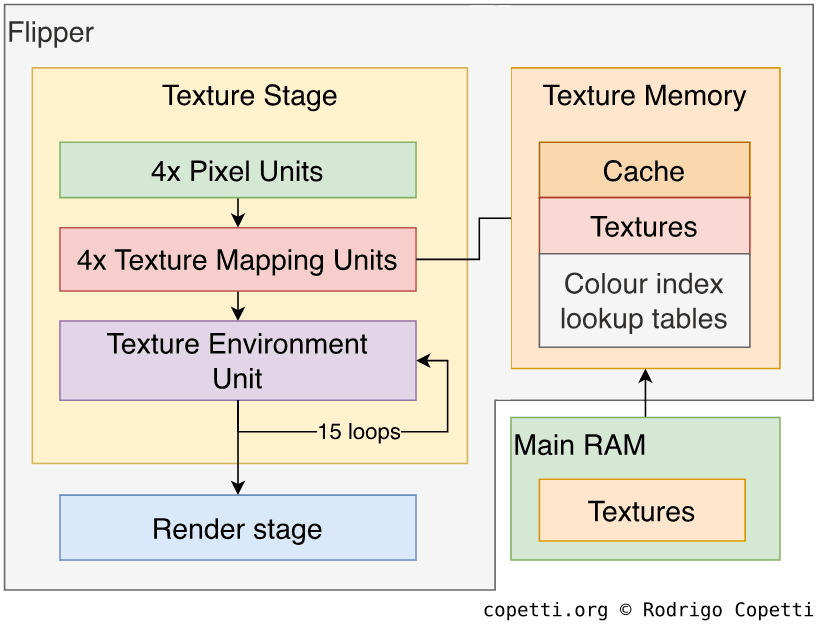
现在是为模型应用纹理和特效的时候了,为此GPU包含多个处理像素的单元。 现在,这是一个非常精密(但也相当复杂)的程序,如果你觉得难以理解,就把它想象成一条处理像素的大流水线吧。 因此,有三组单元可供选择:
- 四个并行像素单元(也称为“像素流水线”): 栅格化我们的基元(将其转换为像素)。 有四个单元可用,每个周期最多可传输2x2像素。
- 每个像素单元的末端有一个纹理映射单元(共四个): 它们在每个循环中为我们的基元(现在只是像素)处理多达八个纹理。
- 纹理环境单元(Texture Environment unit,“TEV”): 这是一个功能强大、可编程的16级色彩混合器。 它基本上结合了多个纹理元素(texels)(光照、纹理和常量)来实现大量纹理效果,这些效果将应用到我们的多边形上。
- 该单元的工作原理是接收四个像素,然后根据要求的操作对其进行处理。 之后,它可以将得到的像素作为新的输入,这样在下一阶段/周期,该单元就可以对之前的结果执行不同类型的操作。 这种“循环”最多可持续15次迭代。
- 每个阶段有24种操作可供选择[20],考虑到结果可以在下一阶段重新处理,因此有~5.64×10511种可能的排列组合!
- 程序员可以在运行时设置 TEV(这意味着它可以随时更改),这一点至关重要,因为它为大量原创素材和效果打开了大门。
所有这一切都得益于1 MB的纹理内存(1T-SRAM 类型),该内存可分为高速缓存和Scratchpad内存(快速 RAM)。 此外,还提供SRTC(S3纹理压缩)纹理实时硬件解压缩功能,可在1 MB 内存中容纳更多纹理。
渲染
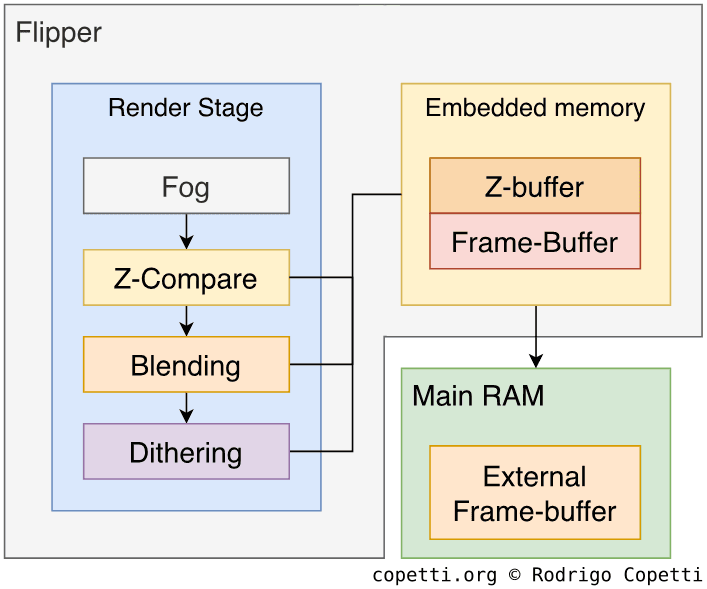
渲染流程的最后阶段包括对场景进行一些可选但有用的润色:
- 雾:将TEV中的最后一种颜色与雾常量颜色混合,以有效模拟多雾环境。
- Z-比较:后期阶段的Z缓冲。 引擎将使用2 MB的嵌入式1T-SRAM进行Z缓冲计算。
- 混合:将当前帧的颜色与上一帧缓冲区的颜色相结合。
- 抖动:顾名思义,对帧进行抖动处理。
生成的帧最终会写入嵌入式1T-SRAM中的帧缓冲区,但它仍被锁定在 Flipper 内部(该区域被称为“嵌入式帧缓冲区”(Embedded Frame Buffer,“EFB”),虽然它也包括Z缓冲区)。 因此,要在电视上显示它,我们必须将其复制到外部帧缓冲区(External Frame Buffer,“XFB”)[21],这可以通过视频接口(Video Interface,“VI”)来获取。 此外,复制过程还可以应用抗锯齿(减少块状边缘)、去闪烁(平滑亮度的突然变化)、RGB到YUV转换(类似格式,占用内存空间更少)和Y缩放(垂直缩放帧)等效果。
值得一提的是,XFB区域也可由CPU操作,这使它能将先前渲染的位图与我们最近渲染的帧结合起来;或者当某些游戏需要渲染色彩非常丰富的帧时,EFB无法容纳这些帧,因此它们被分块渲染,之后由CPU进行合并(始终与VI保持同步)。
交互式比较
是时候将这一切纳入视野了,看看程序员们是如何利用这台游戏机的新图形功能,对以前的游戏设计进行进化的。 别忘了,这些例子都是互动的!
升级
在上一代游戏机中,由于多边形数量的限制,马里奥的模型不得不缩减,而在这一代游戏中,马里奥的模型被完全重新设计,请仔细看看马里奥的模型是如何从素面朝天演变成皱巴巴的袖子的。


 “现代版本”中可用的互动模型
“现代版本”中可用的互动模型320个三角形


 “现代版本”中可用的互动模型
“现代版本”中可用的互动模型4718个三角形
在短短两年时间里,我们获得了如此多的细节,真是令人印象深刻,不是吗?
更新
在这种情况下,Sonic Team已经为其独特的游戏机设计了索尼克模型,但在将游戏移植到GameCube之后,他们发现自己可以在模型上添加更多的多边形,从而获得更好的细节。


 “现代版本”中可用的互动模型
“现代版本”中可用的互动模型1001个三角形


 “现代版本”中可用的互动模型
“现代版本”中可用的互动模型1993个三角形
创造力
从这条流水线的内部工作原理可以看出,图形技术一直在不断发展,现在程序员可以控制渲染过程中的某些功能。

在同一时期,PC显卡开始放弃固定功能的流水线,转而使用着色器核心(运行定义像素操作方式的小程序的单元)。 尽管Flipper仍然包含一个固定功能的GPU,但通过加入TEV单元等组件,可以说任天堂提供了自己的类似着色器的解决方案。
我觉得塞尔达传说:风之杖(The Legend of Zelda: Wind Waker)是利用这种新功能的最佳游戏之一,它采用了一种称为卡通渲染/三渲二(Cel Shading)的独特色彩/光照技术,使纹理看起来很卡通。
视频输出系统
视频信号输出分辨率可达640x480像素(PAL制式为768×576像素),色彩高达1670万种(24位色深)。 此外,该系统还能以逐行模式播放信号(图像更清晰,但当时并非所有电视都支持这种模式)。
XFB可以有多种尺寸,因此出于兼容性的考虑,视频接口会根据区域对XFB进行重新采样,以适应电视屏幕,从而尽力显示帧。
连接
游戏机包含的视频输出接口不是一个,而是两个:

- 其中一个名为模拟A/V输出,实际上就是古老的多路输出。 这是最常用的一种。
- 该游戏机的PAL版本不带 S-Video,NTSC版本不提供RGB(无奈!)。
- 另一种称为数字A/V的电缆以数字形式发送音频和视频(类似于现在的HDMI,但使用的是完全不同的协议!)。
- 任天堂发布了一套分量电缆,可以连接到这个插座。 同一个插头包含一个视频DAC和编码器,用于将数字信号转换为YPbPr(最佳质量)。
- 该电缆作为额外配件出售,现在已被视为某种遗物!
音频
任天堂终于提供了一些专用音频电路,以卸载CPU-GPU的繁重任务,并提供更丰富的音效。 他们的新解决方案是在Flipper中运行旺宏(Macronix)公司生产的独立数字信号处理器(Digital Signal Processor,“DSP”)。
DSP的工作包括对原始音频数据执行不同的操作(如音量变化、采样率转换、3D音效、滤波、回声、混响等),然后输出2通道PCM信号。 然而,DSP并不是单独工作的,它还需要其他组件的帮助来提供音频。
它的第一个伙伴是音频接口(Audio Interface,“AI”),这是一个16位立体声数模转换器,负责通过音频信号将最终样本发送到电视上。 AI每0.25毫秒只能处理32字节的音频数据,因此,如果考虑到每个声音样本多达2字节,而我们需要两个样本来创建立体声,那么AI将能够混合多达8个采样率高达32 kHz的立体声样本!
最后,我们还有音频RAM(ARAM)区块,这是一个很大(16 MB)但速度很慢的备用存储器,可用于存储原始声音数据。 由于空间很大,GPU也可以用它来存储额外的素材(如纹理)。 CPU无法直接访问该内存,因此需要借助DMA来移动内容。
无论好坏,DSP都可以通过使用微码进行编程(哎呀),但不用担心,因为官方SDK已经捆绑了一个通用微码,除了游戏机的启动序列和一些任天堂游戏外,几乎所有游戏都使用了这个微码(真方便,因为任天堂没有记录DSP,所以只有他们知道如何编程)。
话虽如此,声音的产生过程如下[22]:
- CPU命令DMA将原始采样移动到ARAM。
- CPU发送一系列指令,指示DSP如何操作这些采样。 换句话说,CPU上传微码程序(官方只向开发人员提供一个)。
- DSP从ARAM中获取采样,应用所需的操作并将它们混合到两个通道中。 最后,它将得到的数据存储在RAM中。
- AI从RAM中获取经过处理的采样,并通过音频信号输出。
压缩与自由
虽然我们已经进入采样时代,不再受限于特定的波形,但新的声音系统仍然是一个巨大的进步。 首先,强制音乐排序的传奇已经一去不复返了。 现在,系统可以将预先制作好的音乐流畅地传输到音频终端,就像多年前的土星和PS1一样。
让我以两款游戏为例,一款是在任天堂64上发布的游戏,另一款是在GameCube上发布的续集。 两款游戏的配乐不同,但背景(与敌战斗)相同。 考虑到每个系统的设计(共享与专用),看看这两首曲子的音质有何不同。
由RSP实时排序。
DSP音频流传输
如你所听,DSP最终为音乐作曲家提供了他们一直要求的灵活性和丰富性。
其他资料
为了进行更直接的横向对比,我准备了这个互动式小工具,显示作曲家们最终是如何为GameCube及其前身改编乐曲的。 在这里,任天堂64和GameCube都使用了相同的欢快配乐,通过对比,我再次展示了GameCube DSP的技术优势。
N64:星之卡比64:水晶碎片(Kirby 64: The Crystal Shards)(2000)
NGC:星之卡比:空中竞速(Kirby Air Ride)(2003)
现在,为了直观地了解每条音轨背后发生了什么,下面是两张各自的频谱图。 在开始之前,如果您对这类图表不熟悉,我建议您阅读我之前的NES文章,尤其是音频部分(我在那里介绍了这些图表)。
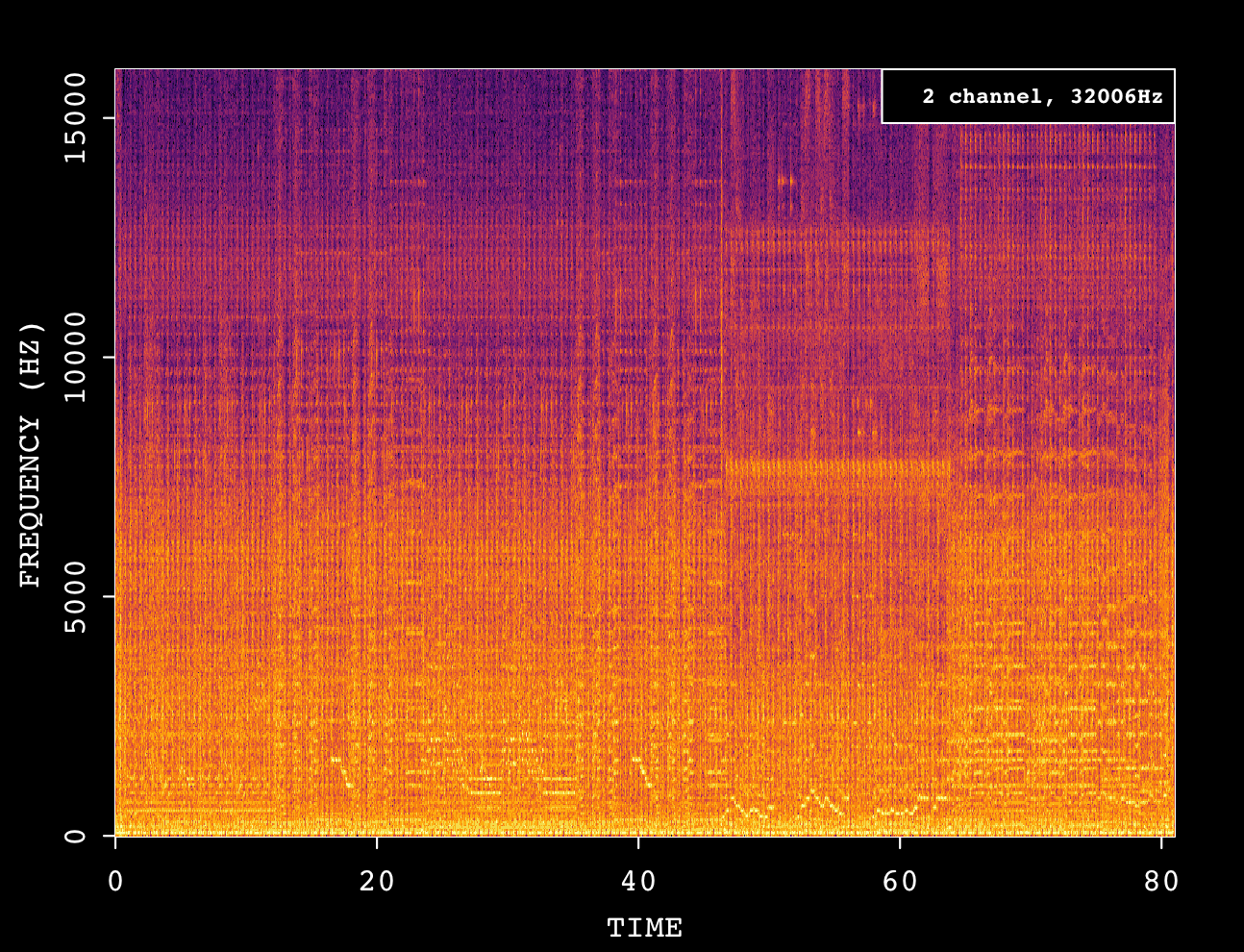

公平地说,混合音轨很难在频谱图中分解,但我相信我可以尝试从中推断出一些规律。
首先,在GameCube曲目中,几乎所有频谱都得到了均匀的利用,这可能是由于伴奏中使用了额外的乐器(增加了谐波,因此填补了频谱图上的更多区域)。
最后,GameCube频谱图上的振幅看起来分布更均匀。 换句话说,每种乐器的音量都有不同程度的平衡,并包含混响等效果。 我猜测后者是作曲家在制作这首乐曲时的初衷,而GameCube支持音频流这一事实使得这类控制成为可能。 因此,作曲家可以使用任何工具对音乐进行排序和混音,而不是严格依赖游戏机(及其局限性)在运行时进行排序和混音。
我不敢说任天堂64完全无法实现同样的效果。 但有一点可以肯定的是,在任天堂64的世界里,每一个音频功能都会耗费额外的周期和/或内存,而这会对游戏的其他方面产生影响。 因此,需要对资源进行合理分配。 另一方面,由于GameCube支持更大的采样,因此可以直接流式传输制作的全部乐谱。
I/O
这一代产品似乎在可扩展性和配件方面下了很大功夫,GameCube包含了几个新的有趣端口,尽管其中一些端口仍未使用。
内部I/O
Flipper负责将CPU与其他组件连接起来,因此除了包含声音和图形电路外,它还提供了一个名为北桥的硬件集合,由以下部分组成[23] :
- 音频接口(Audio Interface,“AI”):连接音频编码器。
- 视频接口(Video Interface,“VI”):连接视频编码器。
- 处理器接口(Processor Interface,“PI”):连接CPU(Gekko)。
- 光盘接口(Disk Interface,“DI”):连接DVD控制器,其本身可视为一台独立的计算机。
- 串行接口(Serial Interface,“SI”):使用专用串行协议连接四个可能的控制器。
- 外部接口(External Interface,“EXI”): 连接外部配件(详见下文)、存储卡和IPL BIOS以及实时时钟(RTC)。 它使用类似SPI的协议,仅使用一个串行节点连接这些设备。
每个接口都有一组寄存器来改变其某些行为。
可选I/O
在GameCube外壳的底部,您可以找到两个外部插座,用于连接一些小部件。


两者在技术上完全相同(串行总线运行频率为32 MHz),但它们的外部形状各不相同,以适应不同的配件:
- 串行端口1:任天堂为该插槽提供了调制解调器和宽带适配器。
- 串行端口2:没有使用该端口的公共配件,但你可能会发现一些提供调试工具的第三方配件。
这些端口通过EXI堆栈运行。
不寻常的 I/O
你会注意到,我还没有提到串行端口旁边的另一个可用插座: 并行端口(Parallel Port)。 这个端口的速度要快得多(8位80 MHz与1位32 MHz),这可能就是任天堂称其为高速端口(Hi-Speed Port)的原因。 但最特别的是,该端口不是通过EXI接入系统,而是通过ARAM!
迄今为止,唯一已知的官方配件是著名的Game Boy Player,它可以作为GameCube的额外底板插入,包含了原生播放Game Boy和Game Boy Advance游戏所需的硬件。 播放器的工作原理是自己完成所有繁重的工作,然后将结果(帧和音频数据)发送到ARAM,GameCube再将其转发给相应的组件进行显示/发声。
一致的设计
我认为值得指出的是,无论连接多少配件,游戏机始终保持立方体形状(或至少试图保持)。
操作系统
打开游戏机后,CPU将开始加载BIOS/IPL芯片上名为Dolphin OS的操作系统,这是一个非常简单的操作系统,将负责初始化硬件,并提供一些方便的系统调用和全局变量供游戏使用。 使用官方SDK开发的游戏将在底层操作中隐含执行这些调用。

启动动画和shell界面
完成启动过程后,操作系统会加载一个非官方称作“主菜单”的小程序。

该程序负责显示著名的启动动画(微立方体绘制GameCube徽标),并在已插入游戏的情况下加载游戏。 在没有有效游戏的情况下,它将提供一个简单的立方体菜单,上面有各种选项可供选择:
- 更改日期和时钟。
- 从DVD光驱加载游戏。
- 管理任何记忆卡上的存档。
- 更改声音设置和屏幕位置。
游戏
任天堂为开发者提供了大量工具,以协助(并鼓励)他们为自己的游戏机开发游戏[24]:
- Dolphin SDK: 官方提供的API和实用库。 其中包括负责为Flipper的GPU编程的GX库。
- C和C++编译器。
- 调试器和测试器: 与官方开发套件配合使用。
- Cygnus:现在称为“Cygwin”,主要用于在Windows上模拟UNIX环境。
- CodeWarrior: 当年事实上的集成开发环境。
- 各种辅助工具,如 MusyX、纹理编辑器、显示列表导出器、USB 编程器等。
- 大量文档! (提供 PDF 和 HTML 版本)
专业硬件
除软件外,该公司还在游戏机公开发布前后提供了不同的硬件套件(价格不等)。
其中最受欢迎的可能是海豚开发硬件(Dolphin Development Hardware,“DDH”),它由一个类似PC的塔式外形组成,包含GameCube的部分I/O接口和大量开发辅助硬件[25],主要用作在Windows PC上开发游戏时的调试站。
存储介质
游戏从一种名为miniDVD的专有光盘中加载,它的大小几乎是传统DVD光盘的一半,最多可容纳1.4 GB的数据。
一个有趣的事实是,光盘读取器以恒定角速度(Constant Angular Velocity,CAV)工作,这意味着如果数据位于光盘的外部区域,则读取速度较快(3.125MB/s),如果数据位于内部区域,则读取速度较慢(2MB/s)。 这与恒定线速度系统(传统CD/DVD光驱使用)不同,后者的效果正好相反。
游戏保存内容存储在一种名为记忆卡的专有外置配件中,有足够的插槽容纳两张记忆卡。
不寻常的控制器
任天堂出品了一种名为GameBoy Link Cable的配件,它可以将Game Boy Advance插入NGC控制器端口,这样游戏就可以将小程序上传到 GBA,并将其视为一个特殊的控制器。 这一有趣的功能使一些游戏能够实现独特的互动和内容。
在线平台
与竞争对手不同的是,任天堂不仅要求用户购买额外的配件才能访问在线内容,而且也没有部署任何可供发行商依赖的互联网服务[26],这就使得开发商必须独自负责提供必要的互联网基础设施。
因此,尽管在线游戏是一种可能的功能,但并未被广泛采用,只有极少数游戏利用了这一功能。
反盗版&自制软件
任天堂在这一领域已经有相当长的时间,因此他们加入安全机制以防止运行未经授权的软件或来自不同地区的游戏并不是什么新闻。 此外,由于GameCube提供了一系列新的输入/输出接口,攻击面大大增加。
安全机制
我们可以把它们归纳为以下几个方面:
DVD控制器
尽管这是任天堂首款使用光盘介质的游戏机,但要想玩盗版游戏并不容易。 miniDVD除了数据加密外,还在光盘内侧使用专有条形码进行保护。 验证和解密过程天衣无缝:miniDVD控制器会进行处理,而系统只限于请求数据。
组成DVD读取器的硬件可以想象成一堵堡垒墙,只有通过一系列命令才能进入,miniDVD控制器有一个专有的CPU,它负责判断插入的光盘是否是真的,如果不是,主CPU发出的任何命令都无法说服它读取光盘。
击破: 与其他猫捉老鼠的游戏一样,第三方公司迟早会成功反向设计控制器,制造出可以欺骗读取器的改机芯片。 但请记住,在不对外壳进行物理改动的情况下,任何改装芯片都无法让这台游戏机神奇地装入传统的CD/DVD!
IPL和EXI
另一种可能的入侵途径是利用外部I/O加载自制程序。 如果不先破解DVD光驱,唯一的办法就是控制GameCube加载的第一个程序,那就是… …IPL。
这意味着,通过反向工程BIOS并用修改过的芯片替换芯片,就可以运行文件阅读器,并执行从附件端口接收的程序(假设插入了额外的硬件)。
尽管如此,IPL芯片是使用XOR条件和密码文本[27]加密的,因此“不可能”进行反向工程。
击破:黑客们最终发现,处理IPL解密的硬件包含一个漏洞,使他们能够捕捉到所使用的密码文本[28]。 有了这个漏洞,他们就可以用相同的密码对另一个ROM进行加密,这样GameCube就能把它当作自己的ROM启动!
如果这还不够,黑客们还找到了新的方法来欺骗miniDVD阅读器,使其加载传统DVD。
荣誉奖
在这两种机制被发现之前,其实还有一种更简单的方法,可以在不做任何修改的情况下加载任意代码。 这种方法就是劫持在线协议。
一些游戏(如梦幻之星OL(Phantasy Star Online))实现了自己的在线功能,可以通过从公司服务器下载更新的可执行文件(DOL文件)来更新,而后者的协议没有实现任何安全性。 因此,正如您所看到的,这是一次蓄势待发的中间人攻击……
长话短说,通过假服务器欺骗,GameCube可以下载(并执行)你提供的任何DOL。 这意味着黑客只需要原版梦幻之星OL游戏碟和宽带适配器。 这种技术被称为PSOload[29]。
这就是全部了,伙计们。

好了,这就是第10篇文章!
我真的想给这篇文章的长度设定一个大致的限制,但你必须明白,技术已经变得如此复杂,如果我不小心跳过任何重要的内容,整个话题就会变得无法跟上。
总之,我要感谢#dolphin-dev IRC社区帮助我了解Flipper GPU的复杂流水线,这些人开发GameCube模拟器已经有好几年了,他们所承受的艰辛令人印象深刻。
最后,如果你觉得这篇文很有趣,请考虑投稿。 我努力使它尽可能完整,在这个过程中,我忘记了它突然花费了我多少时间,不过我觉得这是一项很好的投资。
下篇文章见!
Rodrigo.


